Xorbits Pandas vs. DaskDF vs. Modin vs. Koalas#
Libraries such as Dask DataFrame (short for DaskDF), Pandas API on Spark (short for Koalas),
and Modin aim to support the pandas API on top of distributed computing frameworks. Externally,
these libraries are pandas-like APIs, but they appear quite differently in terms of design and implementation.
In this article, we will compare Xorbits DataFrame (xorbits.pandas) with these libraries
to help you decide which one is right for your needs.
Summary#
Dimension |
Xorbits |
Modin |
DaskDF |
Koalas |
|---|---|---|---|---|
Evaluation Semantics |
Deferred |
Eager |
Lazy |
Lazy |
API Compatibility |
High |
High |
Medium |
Medium |
Ordering Semantics |
Yes |
Yes |
No |
No |
Ecosystem Compatibility |
High |
Low |
High |
Low |
Local Development |
Easy |
Easy |
Easy |
Install Java/Scala/Spark |
GPU |
Yes |
None |
Third-party |
None |
Scalability |
~10TB |
~10GB |
~100GB |
~10TB |
Introduction#
Dask DataFrame is a large parallel dataframe composed of many smaller pandas dataframes. DaskDF is lazily evaluated,
and operations are not immediately executed. Users build a task graph of dataframes and then initiate computation
by explicitly invoking the .compute() function.
Modin is another library that claims to scale Pandas by changing a single line of code. It aims to support the pandas API on preexisting infrastructure, e.g., Modin supports running on both Dask and Ray’s compute engine. Modin uses a modular design so that it can be ported to other computing frameworks. We believe that while being independent of specific computation frameworks does offer flexibility, it can come at the cost of sub-optimal performance. For example, complex tasks (e.g. join) generally require the adaptation of execution frameworks for scheduling and resource management. Framework-agnostic approach may be difficult to achieve the best performance.
Pandas API on Spark (Koalas) delivers the pandas API on Spark. Similar to DaskDF, Koalas also utilizes lazy computation, only commencing computation when the user demands the results. Since Koalas is based on Spark, a mature distributed computing system, it is able to deal with large datasets. In the “Performance Comparison” section, we evaluate the performance of these libraries on large datasets (100GB~1TB). Xorbits demonstrates comparable scalability to Koalas while additionally offering a higher API coverage.
In the following sections, we will carefully compare the differences in terms of semantics and user experience with DaskDF, Koalas, and Modin.
Evaluation Semantics#
DaskDF and Koalas employ lazy evaluation, which delays the computation until users explicitly request the results. Particularly, DaskDF’s API requires users to explicitly invoke .compute() to materialize the computation result. Overall, the need to deliberately trigger computation makes the API less convenient to work with, yet it provides DaskDF and Koalas the chance to perform holistic optimizations across the entire dataflow graph. But we believe this approach is less user-friendly because it places a significant optimization responsibility on the user.
Modin adopts eager evaluation. This evaluation mode is the standard procedure for data scientists when operating with pandas in an interactive setting, such as Jupyter Notebooks. But it may be less efficient if not all the outcomes of computation are needed.
On the other hand, Xorbits employs deferred execution. The benefit of eager evaluation is obvious for interactive data exploration, where users frequently iterate on their dataframe workflows or incrementally build their dataframe queries. Deferred execution bridges the gap between lazy and eager evaluation. More specifically, Xorbits can identify that users often only examine the first or last few rows/columns of the result and then compute this as part of the critical portion (e.g., the operations will influence the results that users inspect) and defer the rest to the non-critical portion. Xorbits will defer the execution of the non-critical portions so it can perform more holistic query planning and optimization. See our blogpost for more details.
API Compatibility#
All those libraries mentioned above achieve parallelism by dividing a large dataframe into smaller partitions that can be processed simultaneously. Consequently, the partitioning scheme chosen by the system determines the pandas API functions that can or cannot be supported.
DaskDF and Koalas only support row-oriented partitioning and parallelism. This method is similar to relational databases.
Conceptually, the dataframe is divided into horizontal partitions along rows, and each partition is processed independently
if possible. When DaskDF or Koalas need to perform column-parallel operations that are to be done independently on columns
(e.g., dropping columns with null values via dropna on the column axis), they either perform very poorly with no
parallelism or do not support that operation. For instance, DaskDF does not implement iloc, MultiIndex,
apply(axis=0), quantile (only approximate quantile is available), median, among others.
Similarly, Koalas does not implement apply(axis=0) (it only applies the function per row partition,
yielding a different result), quantile, median (only approximate quantile/median is available),
MultiIndex, combine, compare, and more.
On the other hand, Xorbits supports both row and column-oriented partitioning and parallelism. In other words, the dataframe
can be conceptually divided into groups of rows or groups of columns. Then Xorbits can transparently reshape the partitioning
as required for the corresponding operation, depending on whether the operation is row-parallel or column-parallel. This allows
Xorbits to support more of the pandas API (e.g., transpose, median, quantile) and do so efficiently.
Modin use the same partitioning scheme as Xorbits, and hence, it also supports as many API functions as Xorbits.
Additionally, Xorbits and Modin both serve as a drop-in replacement for pandas. This means if one API is not yet supported in Xorbits or Modin, it still functions by falling back to running vanilla pandas. If a user decides to go back to use pandas directly, they are not locked in using. In other words, scripts and notebooks written in pandas can be switched to Xorbits or Modin by merely changing the import statement.
Ordering Semantics#
By default, pandas maintains the order of the dataframe, enabling users to anticipate a consistent, ordered perspective while operating on their dataframe. Xorbits conserves the order of the DataFrame, and supports multi-indexing.
Neither DaskDF nor Koalas assure the order of rows in the DataFrame. This is due to DaskDF optimizing the index for computational speed that involves the row index, hence, it does not uphold user-specified order. Similarly, Koalas does not default to supporting order since it may result in performance overhead when working on distributed datasets.
DaskDF additionally does not support multi-indexing. It orders the data based on a single set of row labels for swift row lookups, and constructs an indexing structure based on these labels. The data is both logically and physically stored in the same order.
Ecosystem Compatibility#
Xorbits’s DataFrame and DaskDF align with a larger ecosystem. In addition to pandas, Xorbits also provides Numpy and Scikit-Learn compatible Python libraries, among others. This allows users to scale from their single-machine pandas workflow to a large cluster without significantly changing their code. Similarly, Dask ML and Dask Array align well with the Scikit-Learn and Numpy API, respectively. However, to the best of our knowledge, both Modin and Koalas are lack of Numpy compatible libraries.
Local Development#
Compared with Koalas, using pure Python solution likes Xorbits significantly simplified development and debugging process in a data science workflow. It eliminates the need to install non-Python dependencies like Scala, Java, or Spark for local project execution. Project dependencies can be effortlessly managed with an environment manager, such as Anaconda.
The goal of Xorbits is to bridge the gap between development and production. It empowers you to scale data science and machine learning workloads from your local machine to the cloud without changing a single line of code.
GPU Support#
Xorbits is desgned to work with GPU. Both Xorbits Numpy and Xorbits Pandas support running on GPUs, using CuPy and cuDF
respectively for computation. Users only need to specify gpu=True` when creating the data to execute the computing tasks
in parallel across multiple GPU cards.
Dask supports GPUs through third-party libraries: The RAPIDS provide a GPU-accelerated pandas-like library, cuDF, which interoperates well and is tested against DaskDF. Additionally, Modin and Koalas do not support GPU.
Performance Comparison#
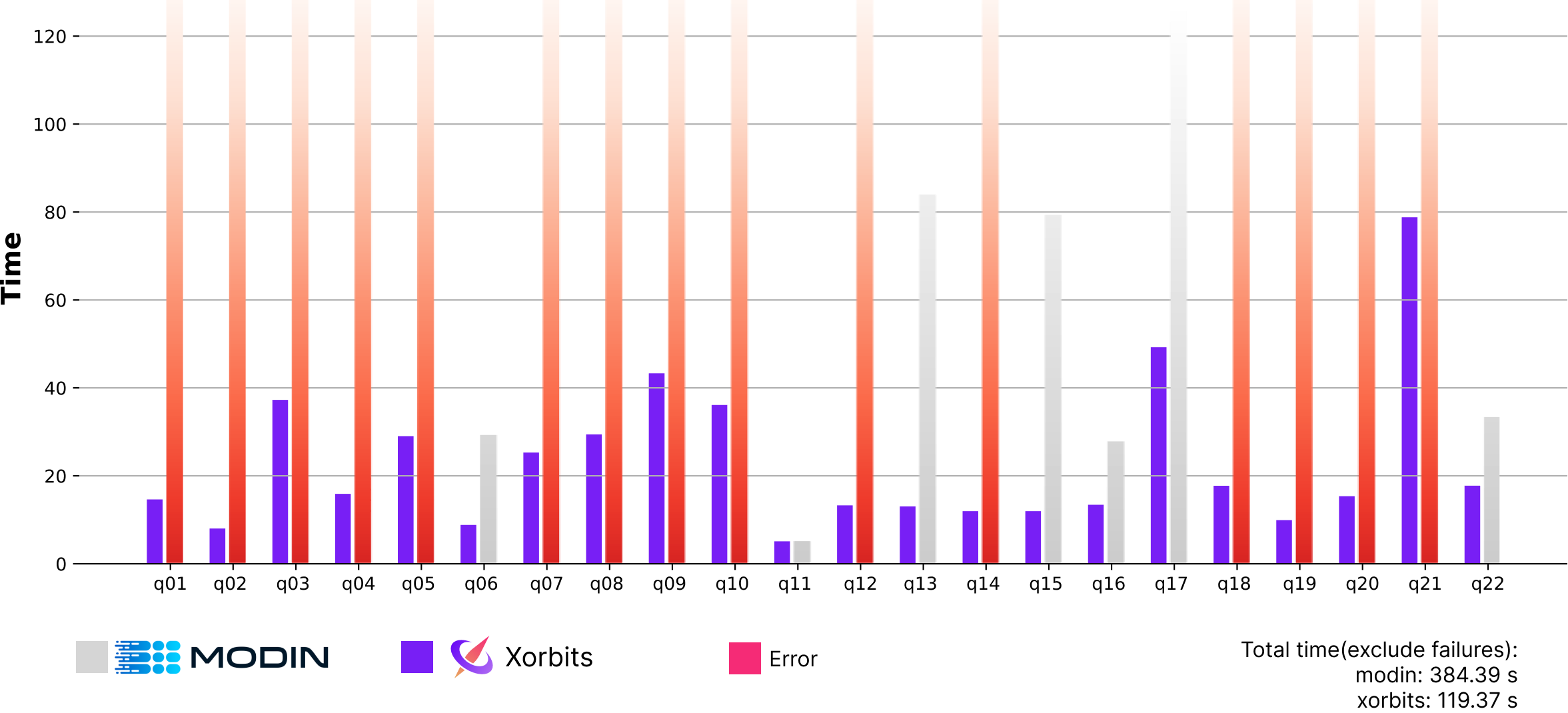
We conducted a performance benchmark using TPC-H benchmark. Across all examined queries in our TPC-H SF100 (~100 GB datasets) benchmark, Xorbits consistently outperformed, being ~8 times faster than DaskDF and ~4 times quicker than Modin. Despite demonstrating a performance comparable to Xorbits, Koalas faced numerous task failures due to API compatibility issues. Our results indicated that Modin encountered memory exhaustion for queries involving substantial data shuffling and failed on those queries. Impressively, Xorbits successfully executed all queries in our TPC-H SF1000 (~1 TB datasets) benchmark, whereas DaskDF, Koalas, and Modin stumbled on most of the queries. For additional details, please refer to our performance benchmarks.
TPC-H SF100: Xorbits vs Dask#

TPC-H SF100: Xorbits vs Koalas#

TPC-H SF100: Xorbits vs Modin#